







SpaceTimePilot: Generative Rendering Across Space and Time
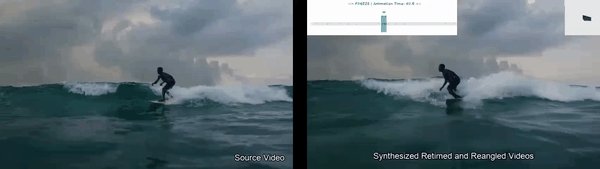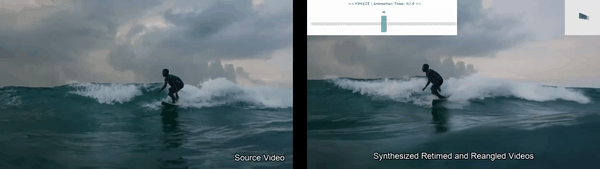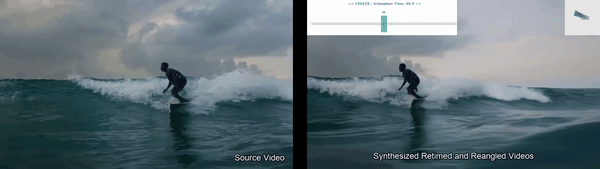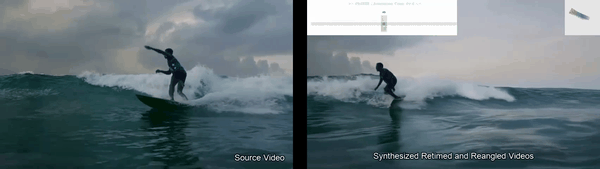
Disentangles space and time in video diffusion for controllable generative rendering. Given a single video, freely steer camera viewpoint and temporal motion across the 4D space-time domain.
Project Page →



